
차밍이
[머신러닝] PCA(principal component analysis) 차원 축소에 대해 본문
0. 차원 축소
- 차원 축소의 필요성
- 실제 데이터들의 대부분은 매우 많은 설명 변수(= 특성 = feature = 흔히 X 값)들을 가지고 있습니다. 따라서 머신러닝 알고리즘을 적용해서 문제를 해결하는 데 있어서 어려움이 많습니다.
- 전체 데이터의 양이 너무 많아서 학습 속도가 느려진다.
- 별로 의미없는 feature들로 인해서 과적합되거나 학습이 잘 되지 않는다.
- 그러므로 feature selection이나 Dimensionality Reduction(차원 축소) 등의 작업이 필요합니다.
- 이번 글에서는 차원 축소에 대해서 알아보겠습니다.
1. 차원의 저주
-
각 변수의 50%영역에 해당하는 자료를 가지고 있다고 할 때, 전체 자료의 얼마만큼을 확보할 수 있는가?

-
머신 러닝에서 하나의 feature가 늘어날 때마다 하나의 차원이 증가합니다.
-
사진(출처:https://jermwatt.github.io/)을%EC%9D%84) 보면서 차원의 저주에 대해서 설명하겠습니다.
- 1차원 : 데이터의 밀도가 3/10 = 전체 데이터의 약 30 % 의 데이터
- 2차원 : 데이터 의 밀도가 1/10 = 전체 데이터의 10 % 의 데이터를 포함
- 3차원 : 데이터의 밀도가 0/10 = 해당 공간에서 전혀 데이터를 포함하지 않음
-
위의 경우처럼 차원이 증가할수록 공간의 부피가 기하 급수적으로 증가하면서 데이터의 밀도가 매우 희소해집니다.
-
데이터가 매우 많고 고르게 있다고 가정하면 1차원에서는 1/3만큼, 2차원에서 1/9만큼, 3차원에서는 전체 데이터의 1/27만큼의 데이터만을 가지고있을 것입니다.
-
데이터셋이 많아지면 기하급수적으로 어렵다.
2. 차원 축소의 필요성
- KNN(k-Nearest Neighborhood)의 경우 변수가 가지는 값을 예측 값으로 하는 모델을 간략하게 해서 생각해 보겠습니다.
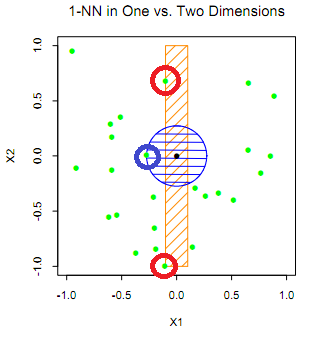
-
1차원에서 KNN을 적용하면 빨간색 두 점을 통해서 검은색 점을 판별할 것입니다.
-
2차원 상에서 KNN을 적용하면 파란색 점을 통해서 검정색 점을 판별할 것입니다.
-
즉, 차원에 따라서 예측 값이 달라질 수 있습니다. 따라서 쓸데없는 feature가 늘어나면 모델 성능에 매우 악영향을 끼칠 수 있습니다.
- 상관계수가 매우 큰 서로 다른 독립 변수
- 예측하고자 하는 변수와 관련이 없는 변수
-
상관계수가 높은 변수 중 일부를 제외
- 상관계수가 0.8인 경우, 변수를 제거하면서 나머지 0.2 부분에 대한 정보가 버려지게 됩니다. 그러므로 차원을 줄이면서 정보의 손실을 최소화하는 방법을 찾아 적용해야합니다.
3. Principal Components
-
차원을 줄이면서 정보의 손실을 최소화하는 방법
-
더 적은 개수로 데이터를 충분히 잘 설명할 수 있는 축을 찾아내야 한다.
-
Principal Components는 공분산이 데이터의 형태를 변형시키는 방향의 축과 그것에 직교하는 축을 찾아내는 과정입니다. 2차원의 경우 공분산이 타원의 장축과 단축과 같은 방향으로 나타내 집니다.

- 새로운 장축과 단축을 X축 Y축과 같은 새로운 2차원 평면으로 생각하여 해당 직선에 정사영을 내려 새로운 좌표를 알 수 있습니다.

- 이를 통해서 새로운 데이터의 Boundary를 알 수 있습니다.

-
아래 그림을 통해서 principle component를 찾기 위한 새로운 축을 찾아가는 과정을 직감적으로 이해하실 수 있을 것입니다.

4. PCA 수행 과정

-
Mean centering
-
SVD(Singular-value decomposition) 수행
- Scikit-Learn에서 PCA를 계산할 때에도 고유값 분해(eigenvalue-decomposition)가 아닌 특이값 분해(SVD, Singular Value Decomposition)를 이용해 계산한다고 합니다. 그 이유는 SVD를 이용하는 것이 계산 속도에 매우 유리하다고 합니다.
-
PC score 구하기
-
PC score를 활용하여 분석 진행
- PC score를 설명변수로 활용하여 분석을 진행합니다.
5. PCA 실습 예제
실제 데이터를 가지고 Python으로 PCA를 적용하여 데이터를 분석한 실습은 다음 포스팅을 통해서 진행해보겠습니다.
- 2020/03/04 - [머신러닝] - [머신러닝] PCA 실습 (2) : 주성분분석이 성능을 높여주는가?
- 2020/03/02 - [머신러닝] - [머신러닝] 실습으로 보는 PCA(주성분 분석)가 필요한 이유
- Reference
'파이썬 > 머신러닝' 카테고리의 다른 글
| [파이썬] 실습 데이터를 사용한 SVM 모델 생성 및 예측, C와 감마(Gamma) (3) | 2020.03.18 |
|---|---|
| [파이썬 머신러닝] Kaggle 타이타닉 데이터 생존자 예측모델 RandomForest와 DecisionTree (1) | 2020.03.16 |
| [파이썬/데이터분석] LendingClub 원금 상환 여부 예측하기(2) 시각화 소스코드 (0) | 2020.03.12 |
| [파이썬/데이터분석] LendingClub 원금 상환 여부 예측하기(1) : EDA와 데이터 시각화 (0) | 2020.03.12 |
| [머신러닝] PCA 실습 (2) : 주성분분석이 성능을 높여주는가? (2) | 2020.03.04 |
| [머신러닝] 실습으로 보는 PCA(주성분 분석)가 필요한 이유 (3) | 2020.03.02 |
| Machin Learning의 개념 (0) | 2020.01.28 |
| [Kaggle] Bike Sharing Demand 자전거 수요 예측 (0) | 2020.01.21 |


